RMAN-03009 and ORA-27052 Due to Opportunistic Locking
12/31/2012 12:20:00 PM
While backing up backup sets to a secondary location which was a Windows share, RMAN job failed with the following error:
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03009: failure of backup command on ORA_DISK_1 channel at sometime
ORA-27052: unable to flush file data
Linux-x86_64 Error: 5: Input/output error
When I digged up a little bit, I found the following lines in server's system log:
<host> kernel: CIFS VFS: No response to cmd 47 mid 2921
<host> kernel: CIFS VFS: Write2 ret -11, wrote 0
<host> kernel: CIFS VFS: Write2 ret -112, wrote 0
<host> kernel: CIFS VFS: Write2 ret -11, wrote 0
<host> kernel: CIFS VFS: Write2 ret -11, wrote 0
The problem was caused by optimistic locking property of CIFS module. If the file you are copying is large enough (in my case it was about 80 GB) through a CIFS channel, you may hit this problem. By default optimistic locking is set to 1 when the module is loaded. Disabling optimistic locking solves the problem with no performance drawback, at least I haven't observed.
To disable optimistic locking:
$ echo 0 > /proc/fs/cifs/OplockEnabled
ETL with Bulk Insert Using ODP.Net
12/12/2012 01:48:00 AM
First one is row-by-row basis. Pseudo code representing the case is as below:
For each row in the file
Read row;
Do transformations of the row;
Insert row;
loop;
To execute insert statements, I will use the method below. It takes advantage of bind variable to avoid hard parsing.
private void ExecuteNonQuery(string commandText, Dictionary<string, object> parameters)
{
using (OracleCommand comm = new OracleCommand(commandText))
{
if (orclConn.State != System.Data.ConnectionState.Open)
orclConn.Open();
comm.Connection = this.orclConn;
foreach (KeyValuePair<string, object> kvp in parameters)
comm.Parameters.Add(kvp.Key, kvp.Value);
comm.ExecuteNonQuery();
}
}
Begin a transaction: OracleCommand comm = GetTransaction();
For each row in the file
Read row;
Do transformations of the row;
Insert row: ExecuteNonQuery(comm, "<insert statement>", parameters);
loop
Commit transaction: comm.Transaction.Commit();
Methods referenced above are:
private OracleCommand GetTransaction()
{
OracleTransaction dbTran = this.BeginTransaction;
OracleCommand comm = new OracleCommand();
comm.Connection = this.orclConn;
comm.Transaction = dbTran;
return comm;
}
private void ExecuteNonQuery(OracleCommand comm, string commandText, Dictionary<string, object> parameters)
{
comm.CommandText = commandText;
foreach (KeyValuePair<string, object> kvp in parameters)
comm.Parameters.Add(kvp.Key, kvp.Value);
comm.ExecuteNonQuery();
}
- Every three seconds,
- When someone commits,
- When switching log file,
- When redo buffer gets full 1/3 of it or has 1 MB of cached redo log data
To insert rows using array binding, required code:
These are the good, the bad and the ugly (if we skip using bind variable, it could be uglier) methods of bulk insert.
Changing IP Addresses of a 11g RAC
11/30/2012 05:37:00 PM
There are three phases for changing IP addresses of an Oracle Cluster related to three groups of networks used; public, VIP and SCAN. Below you may find the steps to alter IP addresses of a 11g RAC installation running on Oracle Linux 5. Be sure you follow the steps in order because changes for public network should be done before VIP network changes.
Changing Public IPs
1. Check current network information:
$ $GRID_HOME/bin/oifcfg getif
eth0 10.10.11.0 global public
eth1 192.168.0.0 global cluster_interconnect
2. Delete the existing interface information from OCR
$ $GRID_HOME/bin/oifcfg delif -global eth0/10.10.11.0
3. Add it back with the correct information
$ $GRID_HOME/bin/oifcfg setif -global eth0/10.10.12.0:public
4. Shutdown the cluster
$ crsctl stop cluster -all
5. Modify the IP address at network layer, DNS and /etc/hosts file to reflect the change. Files to modify/check are:
- /etc/sysconfig/network-script/ifcfg-eth0
- /etc/sysconfig/network
- /etc/hosts
Restart network interface to activate changes
$ ifdown eth0
$ ifup eth0
6. Restart the cluster
$ crsctl start cluster -all
Changing VIPs
1. Check current configuration
$ srvctl config nodeapps -a
Network exists: 1/10.10.11.0/255.255.255.0/eth0, type static
VIP exists: /racnode1-vip/10.10.12.11/10.10.12.1/255.255.255.0/eth0, hosting node racnode1
VIP exists: /racnode2-vip/10.10.12.12/10.10.12.1/255.255.255.0/eth0, hosting node racnode2
2. Stop the database instance and VIP:
$ srvctl stop instance -d <db_name> -n racnode1
$ srvctl stop vip -n racnode1 -f
3. Ensure VIP is offline and VIP is not bounded to network interface
$ crsctl stat res -t
$ ifconfig -a
4. Modify the IP address at network layer, DNS and /etc/hosts file to reflect the change
5. Alter the VIP
$ srvctl modify nodeapps -n racnode1 -A 10.10.12.12/255.255.255.0/eth0
6. Verify the change
$ srvctl config nodeapps -n racnode1 -a
VIP exists.: /racnode1-vip/10.10.12.12/255.255.255.0/eth0 hosting node racnode1
7. Start the database instance and VIP
$ srvctl start vip -n racnode1
$ srvctl start instance -d <db_name> -n racnode1
8. Ensure VIP is online and VIP is bounded to network interface
$ crsctl stat res -t
$ ifconfig -a
9. Repeat the steps above for the other nodes in the cluster
Changing SCAN IPs
1. Update DNS with the new IP addresses. If host file is used, change IP in the host file.
2. Stop the SCAN listener and the SCAN
$ $GRID_HOME/bin/srvctl stop scan_listener
$ $GRID_HOME/bin/srvctl stop scan
$ $GRID_HOME/bin/srvctl status scan
3. Check the current IP address(es) of the SCAN
$ $GRID_HOME/bin/srvctl config scan
SCAN name: <scan_name>, Network: 1/10.10.12.0/255.255.255.0/eth0
SCAN VIP name: scan1, IP: /<scan_name>/10.10.11.15
4. Refresh the SCAN with the new IP addresses from the DNS entry:
$ $GRID_HOME/bin/srvctl modify scan -n <scan_name>
5. Check whether the SCAN has been changed
$GRID_HOME/bin/srvctl config scan
SCAN name: <scan_name>, Network: 1/10.10.12.0/255.255.255.0/eth0
SCAN VIP name: scan1, IP: /<scan_name>/10.10.12.15
You can refer to documents; [ID 276434.1] for public and VIP network changes and [ID 952903.1] for SCAN IP changes for detailed information.
Oracle R Enterprise Output Error: ORA-22621
11/29/2012 10:21:00 AM
Embedding R into Oracle database is a terrific idea. I believe anyone practicing data analysis and/or data mining should should take look at it. Although it's not a mature environment yet, some workarounds may be needed sometimes. Such as the one I come up against recently. To be clear beforehand, I'm running Oracle R Enterprise 1.1 on a 11.2.0.3 database. To illustrate the problem here is a demonstration:
Create a embedded function which returns a data frame/table with three columns which are type of integer, decimal and character respectively:
begin
sys.rqScriptCreate('Test',
'function(){
data.frame(a=1:10, b= seq(0.1, by=0.1),c=letters[1:10])
}');
end;
/
And call it within a query:
select a, b, c
from table(rqsys.rqEval(null,
'select 1 a, 1 b, cast(''c'' as varchar2(30)) c from dual',
'Test'));
Which will result with error:
ORA-22621: error transfering an object from the agent
ORA-06512: at "RQSYS.RQTABLEEVALIMPL", line 60
22621. 00000 - "error transfering an object from the agent"
*Cause: Any error returned from pickler routines on the agent side.
*Action: Contact Oracle Support.
The actual problem is the output format in fact. rq*Eval() functions takes output table definition as a parameter and it works smoothly with numeric columns, yet same cannot be said for character based columns. The workaround I came up with is taking advantage of good old XML. If you call the function with XML option instead of giving table format definition, you have the result set without an error. So keep on going this way and process the output which is CLOB containing XML:
select x.*
from table(rqsys.rqEval(null, 'XML', 'Test')) t,
xmltable('//root/frame_obj/ROW-frame_obj' passing xmltype.createxml(t.value)
columns a varchar2(1) path 'a/text()',
b varchar2(3) path 'b/text()',
c varchar2(1) path 'c/text()')(+) x;
Database Triggers
10/31/2012 12:15:00 PM
Database triggers are well-matched ways of monitoring your database and logging events you'd like know about. It's possible to capture errors occurred and even notify yourself for exceptional situations. An example of these benefits is what I'll briefly present here. Below you'll find a demonstration of a trigger which logs errors and sends a mail when out of space error occurs.
First of all, start with creating the table to log into:
CREATE TABLE SERVERERROR_LOG
(
ERROR_TIME TIMESTAMP,
DB_USER VARCHAR2(30),
OS_USER VARCHAR2(30),
USER_HOST VARCHAR2(64),
CLIENT_PROGRAM VARCHAR2(48),
SQLID VARCHAR2(13),
ERROR_STACK VARCHAR2(2000)
);
Table keeps records of SQL running (actually ID of the SQL to save space, since full SQL text can be queried) and the error it caused beside client information. Here is the trigger:
CREATE OR REPLACE TRIGGER log_server_errors
AFTER SERVERERROR ON DATABASE
DECLARE
osuser VARCHAR2(30);
machine VARCHAR2(64);
prog VARCHAR2(48);
sqlid VARCHAR2(13);
err_type VARCHAR2(19);
obj_type VARCHAR2(19);
owner VARCHAR2(30);
ts VARCHAR2(30);
obj VARCHAR2(30);
sub_obj VARCHAR2(19);
BEGIN
SELECT osuser, machine, program, sql_id
INTO osuser, machine, prog, sqlid
FROM gv$session
WHERE audsid = userenv('sessionid') and inst_id = userenv('instance') and status = 'ACTIVE';
INSERT INTO servererror_log VALUES
(systimestamp, sys.login_user, osuser, machine, prog, sqlid, dbms_utility.format_error_stack);
COMMIT;
IF (SPACE_ERROR_INFO(err_type,obj_type,owner,ts,obj,sub_obj) = TRUE) THEN
UTL_MAIL.SEND( sender => 'oradb@xyz.com',
recipients => 'dba@xyz.com',
subject => 'Insufficient Tablespace Size',
message => err_type || ' at tablespace ' || ts
);
END IF;
END log_server_errors;
Trigger queries gv$session view to gather client information and inserts to log table. Then, if error is a out of space error, trigger sends an e-mail using UTL_MAIL package. This's a pretty straightforward trigger you can use and improve according to your needs.
Upgrading Oracle Enterprise Manager 12c R1 to 12c R2
9/14/2012 05:45:00 PM
1. Download installation files from OEM Downloads page and unzip them. A disk space of 5.3 GB is required for decompressed installation files.
2. Stop OMS. You can also stop the service when installer prompts you to say it is still running.
$ emctl stop oms
3. Run the installer
$ ./runInstaller






As a prerequisite, emkey should be configured properly. Run the following command:
$ emctl config emkey -copy_to_repos_from_file -repos_host <host_fqdn> -repos_port <port_number> -repos_sid <database_sid> -repos_user sysman -emkey_file /u01/app/Oracle/Middleware/wlserver_10.3.5/oms/sysman/config/emkey.ora






During installation process, repository database is also upgraded.

NFS Sharing for Linux
9/13/2012 06:14:00 PM
Sharing a directory using NFS to other Linux systems is a common and handy way. To be able to explain briefly, let me separate tasks into two as server and client side. I use Oracle Linux 6 and Oracle Linux 5 respectively as server and client, though just the opposite goes through same steps. However these commands should run on every Red Hat based system.
On the server that you will create the share, edit the export file:
$ vi /etc/exports
Add line(s) to file such as:
/share_dir *(rw,sync,fsid=0)
and/or
/shares/nfs 192.168.101.11(ro,sync,fsid=0)
Pay attention not to use extra space on a line, it may cause a problem. Here, instead of "*" - which means sharing is for every one, to world - you can use client's IP or FQDN as shown above. Also if it's going to be read-only share write "ro" instead of "rw". We use "fsid=0" parameter not to get "mount.nfs4: Operation not permitted" error.
Permissions of directory, "/share_dir" and/or "/shares/nfs", should be read and execute to others if it's a read-only share or read-write and execute to others if it's writable. Otherwise you will face with "mount.nfs4: Permission denied" error when mounting the share. So alter permissions of directory:
$ chmod 757 /share_dir
Restart related services (If your server is Linux 5, use portmap instead of portreserve. ):
$ /etc/init.d/portreserve restart
$ /etc/init.d/nfs restart
You can check shares by:
$ showmount -e <server_ip>
$ exportfs -avr
On the client simply mount the share by:
$ mount -t nfs4 <server_ip_or_host_name>:/ /mnt
Notice that, even the shared directory is "/share_dir" or "/shares/nfs" we use "/" only.
Retrieving Index Usage Statistics
8/29/2012 11:31:00 AM
Indexes are old friends of every DBA. To check out what your friends are up to, in Oracle, basic way is enable monitoring for the index by:
alter index IX_FOO nomonitoring usage;
However what is lacking in this way of monitoring is statistics. You can see whether index is used but cannot see how many times or how it is used. Fortunately Oracle provides many V$ views. The query below returns basic statistics about your indexes. How it is used (range or full scan etc.), how many times and when was the last time it was used:
select sp.object_name as index_name,
sp.options,
sum(sa.executions) as executions#,
max(timestamp) as last_used
from v$sql_plan sp, v$sqlarea sa
where sa.address = sp.address
and sa.hash_value =sp.hash_value
and sp. operation = 'INDEX'
and object_owner in ('SCOTT')
group by object_name, options
order by 3 desc;
With Exadata, we've started to use less indexes and even dropped some existing ones. Because we want to use Exadata features like storage indexes and smart scan instead, we let the cells do their job. On Exadata we prefer to see fast full scans instead of range scans. To see Exadata specific statistics related to indexes, you can add columns with prefix "io_cell" in V$SQLSTATS or V$SQLAREA views. Such as:
select sp.object_name as index_name,
sp.options,
sum(sa.executions) as executions#,
max(timestamp) as last_used,
sum(sa.disk_reads) as disk_reads,
sum(sa.direct_writes) as direct_writes,
sum(sa.io_cell_offload_eligible_bytes)/1024/1024 as offloadable_mb,
sum(sa.io_cell_offload_returned_bytes)/1024/1024 as offloaded_mb,
sum(sa.rows_processed) as rows_processed
from v$sql_plan sp, v$sqlarea sa
where sa.address = sp.address
and sa.hash_value =sp.hash_value
and sp. operation = 'INDEX'
and object_owner in ('SCOTT')
group by object_name, options
order by 3 desc;
There are many other statistics you can find in V$ views, so you can improve the query according to your needs.
ORA-08104 While Rebuilding Index
7/30/2012 11:22:00 AM
If a session has failed or cancelled by user while rebuilding an index online, when another user/session tries to rebuild or drop the same index may face with the following error:
ORA-08104: this index object 123456 online is being built or rebuilt
The reason beneath is that data dictionary has been left in a state reflecting a rebuild is on going, in fact it is not.
To solve the issue simply run the following:
DECLARE
RetVal BOOLEAN;
OBJECT_ID BINARY_INTEGER;
WAIT_FOR_LOCK BINARY_INTEGER;
BEGIN
OBJECT_ID := 123456;
WAIT_FOR_LOCK := NULL;
RetVal := SYS.DBMS_REPAIR.ONLINE_INDEX_CLEAN (OBJECT_ID);
COMMIT;
END;
/
Adding Hints with SQL Patch
7/25/2012 02:19:00 PM
As a DBA, time to time, you may wish to add a hint to a query sent by a developer or a third party application. Actually this is possible by using SQL Patch. Essentially SQL Patch is the recommendation provided by SQL Repair Advisor. When you apply the patch, it directs optimizer to the way it suggested. This issue has been revealed by a Oracle blog, let's try it in a different way. Let's say you want to run the query below in parallel:
select count(*) from stage
To add PARALLEL hint to the query with SQL Patch:
begin
dbms_sqldiag_internal.i_create_patch(
sql_text => 'select count(*) from stage',
hint_text => 'PARALLEL(stage,2)',
name => 'test_parallel_patch');
end; /
When you run the query, you will see that it didn't run in parallel. To confirm you can run the query below and see no rows returned.
select px_maxdop, sql_id, sql_text
from v$sql_monitor
where sql_text = 'select count(*) from stage';
However if you check the execution plan, you will see the statement "SQL patch "test_parallel_patch" used for this statement" under the note section. So SQL Patch is applied though not run as accepted. There is a workaround for the problem. Display execution plan with outline option first:
explain plan for select count(*) from stage; select * from table(dbms_xplan.display(format=>'+OUTLINE'));
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$1" "STAGE"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
DB_VERSION('11.2.0.3')
OPTIMIZER_FEATURES_ENABLE('11.2.0.3')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Drop the SQL Patch you have created:
begin
DBMS_SQLDIAG.DROP_SQL_PATCH(name => 'test_parallel_patch');
end;
/
Recreate it as:
begin
dbms_sqldiag_internal.i_create_patch(
sql_text => 'select count(*) from stage',
hint_text => 'PARALLEL(@"SEL$1" "STAGE"@"SEL$1",2)',
name => 'test_parallel_patch');
end; /
Notice that we changed table name with the one displayed in execution plan's Outline Data section. Run the query again and see that it runs in parallel, execution plan says:
Note
--------
- Degree of Parallelism is 2 because of
- SQL patch "test_parallel_patch" used for this statement
This situation does not takes place if you use a hint without a table name, such as using PARALLEL(2) instead of PARALLEL(stage,2), or a hint not requiring a table name.
ORA-02289 While ore.sync() in Oracle R Enterprise
6/08/2012 07:24:00 PM
After connecting to your Oracle database through R console and run the command ore.sync, you may have faced with:
error. If you trace queries running while the sync command is in progress, you will see the one below:
CREATE PUBLIC SYNONYM RQ$OBJECT_SEQ FOR RQSYS.RQ$OBJECT_SEQ;
Adding New Disks to an Existing ASM Disk Group
5/18/2012 06:23:00 PM
When the free disk space level starts getting lower and lower, it is time to add disk(s) to feed your database. Most likely and advisable, your database is running on ASM (Automatic Storage Management) which provides abstraction over physical disks perfectly. Here are the steps of adding new disks:
1. Add new disks to your server physically. Assuming your database is running on a server class system or as a virtual machine, it is possible to add disks without shutting down the server through SCSI interface either way.
2. Force Linux to discover new disks without need to reboot:
$ echo "- - -" > /sys/class/scsi_host/host0/scan
$ fdisk -l
$ ls /dev/sd*
3. Create a partition on each newly discovered disks:
4. Mark each disk as ASM disks:
5. To add disks to a ASM disk group, as oracle run asmca tool.

Right click the disk group to be expanded and select "Add Disks"

Select disk(s) to add from the eligible disks list and click OK. When you return the first screen notice that free space is increased.
Configuring SQL Server Plug-in for OMS 12c
5/14/2012 06:17:00 PM
- "View any database", "View any definition" and "View any database" on server
- Public role in each database, except master and tempdb, since public server role covers necessary access to them. Since login is added to model database, newly created databases from now on will also include this grant.
- Execute on msdb.dbo.sp_help_job stored procedure.

Oracle Database Network Bandwidth Usage
4/29/2012 03:25:00 PM
(
select sysdate, max(value) as max_val, avg(value) as avg_val
from gv$sysmetric_history
The formulation to calculate bandwidth is:
Required bandwidth = ((Redo rate bytes per sec. / 0.7) * 8) / 1,000,000 = bandwidth in Mbps
Since you have collected enough data, you can figure out the peak and average bandwidth:
from bandwidth;
Upgrading Oracle Enterprise Manager 11g Grid Control to 12c Cloud Control with Exadata Plug-ins
4/26/2012 06:21:00 PM
Upgrading 11g Grid Control to 12c Cloud Control with 1-System Upgrade Approach:
$ unzip p6880880_111000_Linux-x86-64.zip -d <OMS_HOME>/
$ unzip p10065631_111010_Generic.zip
$ <OMS_HOME>/OPatch/opatch prereq CheckConflictAgainstOHWithDetail -phBaseDir ./10065631
If no conflict is found
$ <OMS_HOME>/bin/emctl stop oms
$ cd 10065631
$ <OMS_HOME>/OPatch/opatch apply
$ export ORACLE_HOME=<OMS_HOME>
$ <OMS_HOME>/bin/rcuJDBCEngine sys/<Password>@<host_name>:<db_sid> JDBC_SCRIPT post_install_script.sql $PWD $ORACLE_HOME
$ <OMS_HOME>/bin/rcuJDBCEngine sys/<Password>@s<host_name>:<db_sid> JDBC_SCRIPT post_install_pactht.sql $PWD $ORACLE_HOME
$ <OMS_HOME>/bin/emctl start oms
3. Now we can install preupgrade patch. You can download it from OTN.
$ unzip p13597150_111010_Generic.zip
$ <OMS_HOME>/bin/emctl stop oms
$ <OMS_HOME>/bin/emctl start oms
$ cd 13597150
$ <OMS_HOME>/OPatch/opatch apply
$ <OMS_HOME>/bin/rcuJDBCEngine sys/<Password>@<host_name>:<db_sid> JDBC_SCRIPT $ORACLE_HOME/sysman/preupgc/puc_dblink_pkgdef.sql
$ <OMS_HOME>/bin/rcuJDBCEngine sys/<Password>@<host_name>:<db_sid> JDBC_SCRIPT $ORACLE_HOME/sysman/preupgc/puc_dblink_pkgbody.sql
$ <OMS_HOME>/bin/rcuJDBCEngine sysman/<Password>@<host_name>:<db_sid> JDBC_SCRIPT $ORACLE_HOME/sysman/preupgc/pre_upg_console.sql
$ <OMS_HOME>/bin/emctl start oms
When you click on validate a job will run and analyze your agent(s). Your agent(s) might fall into one of these groups:
- Completely Upgradable - A non-windows agent with no or upgradable plugins.
- Missing Plug-Ins Software - A non-windows agent with not upgradable plugins. My agents falls in this category since it is a Linux agent with Exadata plugins. Starting from 12c, Exadata features are included in OEM, so no plugin is required.
- Missing Agent Software - Agent software is not available
- Not Supported - A Windows agent
5. After verifying agent(s), upgrade them by following steps below described in Oracle documentation. First three steps will create a job, you can find job output screen in each step:
a) Deploy and configure the software binaries of Oracle Management Agent 12c

b) Generate a health report and check the readiness of the predeployed Management Agents

c) Verify and sign off the health check report
d) Switch over the old Management Agents to the newly deployed ones so that they can communicate with Enterprise Manager Cloud Control
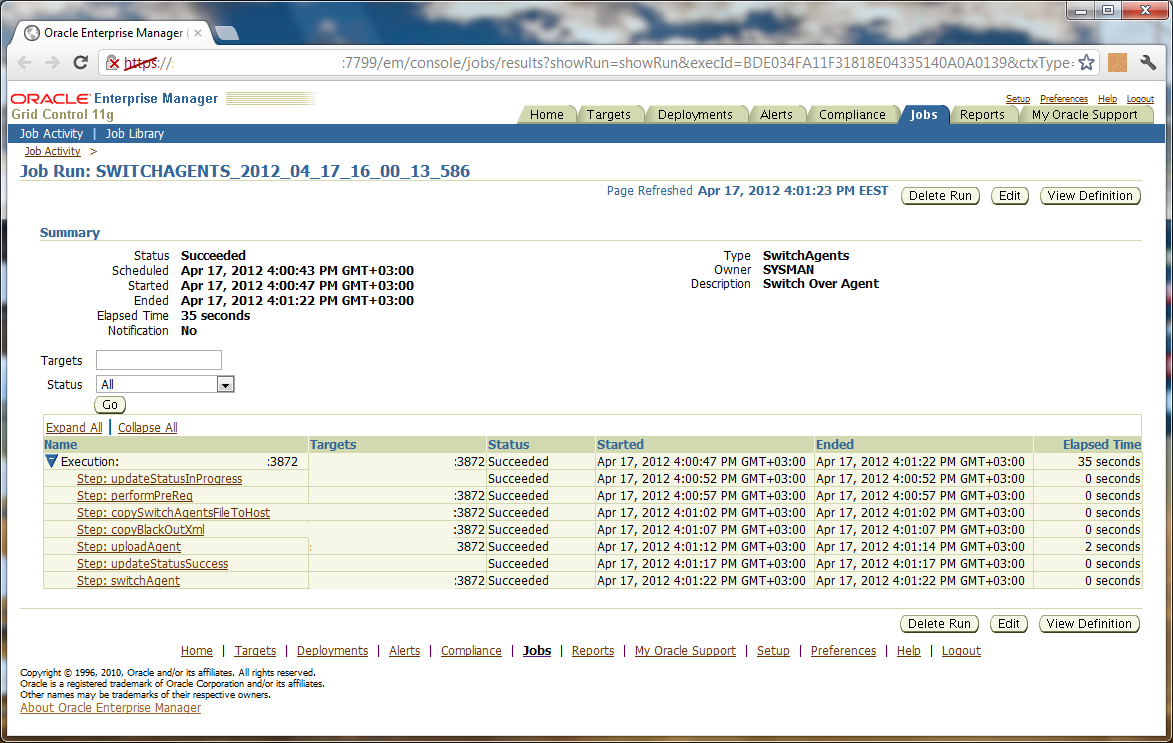
Check the status of upgraded agent:
---------------------------------------------------------------
Agent Version : 12.1.0.1.0
OMS Version : (unknown)
Protocol Version : 12.1.0.1.0
Agent Home : <AGENT12c_HOME>/agent_inst
Agent Binaries : <AGENT12c_HOME>/core/12.1.0.1.0
Agent Process ID : 19089
Parent Process ID : 18963
Agent URL : https://<host>:3872/emd/main/
Repository URL : https://<host>:4900/empbs/upload
Started at :
Last Reload : (none)
Last successful upload : (none)
Last attempted upload : (none)
Total Megabytes of XML files uploaded so far : 0
Number of XML files pending upload : 69
Size of XML files pending upload(MB) : 0.07
Available disk space on upload filesystem : 21.46%
Collection Status : Collections enabled
Last attempted heartbeat to OMS :
---------------------------------------------------------------
Agent is Running and Ready
$ <OMS_HOME>/bin/emctl stop oms
$ ./runInstaller












You may now log on to new OMS Console.
Discovering Exadata Through 12c
OMS_LOCATION = MY_GC
EM_BASE = / u01/app/embase
OMS_HOST = oemserver.company.com
OMS_PORT = 4900
EM_USER=oracle
EM_PASSWORD=<password>
Do check the port number by running following command on OEM server:
To install agent, as root:

Installing Oracle R Enterprise
3/20/2012 07:02:00 PM
Oracle has integrated popular statistical package R as a component of database's Advanced Analytics Option. Oracle R Enterprise comes with Big Data integrated too. It also can be installed separately to 11 R2 databases on Oracle Linux 5 64-bit and naturally to Exadata. I'll try to briefly explain how you can install it.
Prerequites:
1. If not already enabled, enable yum repos for Oracle. You can find out how from Oracle public yum site.
2. Install R
$ yum install R.x86_64
Installing Client on Windows:
1. Next thing to be done is installing client tool. Download R for Windows from R Project and install it.
2. Download Oracle R Enterprise Client Packages and Client Supporting Packages for Windows from OTN and unzip them.
3. To install packages; run R from All Programs as administrator, from the menu: Packages -> Install package(s) from local zip files:
a. Navigate to <unzip_dir>\ore-supporting-windows-1.0\bin\windows\contrib\2.13
b. Select; DBI_0.2-5.zip, png_0.1-4.zip and ROracle_1.1-1.zip
c. Click open:
package 'DBI' successfully unpacked and MD5 sums checked
package 'png' successfully unpacked and MD5 sums checked
package 'ROracle' successfully unpacked and MD5 sums checked
d. Repeat the step for client packages. Navigate to <unzip_dir>\ore-windows-1.0\bin\windows\contrib\2.13
e. Select; ORE_1.0.zip, OREbase_1.0.zip, OREeda_1.0.zip, OREgraphics_1.0.zip, OREstats_1.0.zip, ORExml_1.0.zip
f. Click open:
package 'ORE' successfully unpacked and MD5 sums checked
package 'OREbase' successfully unpacked and MD5 sums checked
package 'OREeda' successfully unpacked and MD5 sums checked
package 'OREgraphics' successfully unpacked and MD5 sums checked
package 'OREstats' successfully unpacked and MD5 sums checked
package 'ORExml' successfully unpacked and MD5 sums checked
Installing Server:
1. To install server download ore-server-linux-x86-64-1.0.zip from OTN.
2. Extract files
$ tar xzf ore-server-linux-x86-64-1.0.tar.gz
$ export R_HOME=/usr/lib64/R
$ export ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1
4. Install
$ cd ore-server-linux-x86-64-1.0/
$ ./install.sh
5. Enable R for the user:
SQL> grant rqrole to <user_name>
To connect your database through R run R client:
R> ore.connect(user="<user_name>", sid="<DB_SID>", host="<host_name>", password="<password>", port = 1521)
R> ore.sync
R> ore.attach()
R> ore.ls()
R> help(Startup)
Core Dumps After Upgrading Grid Infrastructure to 11.2.0.2
3/13/2012 11:52:00 AM
After upgrading Grid Infrastructure from 11.2.0.1 to 11.2.0.2 on a single instance, you may observe huge amount of increase in disk usage due to core dump creation. You will see that a directory named like core_123 created every 10 minutes in <Grid_Home>/log/<host_name>/diskmon.
There is a bug numbered 10283819 in MOS considers the problem , however no workaround is provided. There are two ways you can follow to handle situation. First one is upgrading to 11.2.0.3. And the other one is uninstalling 11.2.0.1 completely, even remove the empty home, and restart all Oracle services.
How to move a datafile from a ASM disk group to another
2/27/2012 07:16:00 PM
I'll explain two ways of moving a datafile from a ASM disk group to another disk group. As you might guess, during migration of the data file you need to take whether the whole tablespace or just the the datafile offline, which makes the difference between two approaches I'm about to explain.
Here is the first way:
1. Find the name of the datafile that you're going to migrate:
SQL> SELECT FILE_NAME FROM DBA_DATA_FILES WHERE tablespace_name = 'EXAMPLE';
2. Take the tablespace offline:
SQL> alter tablespace example offline;
3. Copy the file using RMAN:
RMAN> COPY datafile '+RECOVERY/orcl/datafile/example.123.123456789' to '+DATA';
4. Change datafile's name to the name displayed as output of the command above:
SQL> ALTER DATABASE RENAME FILE '<old_name>' TO '<output file name written at rman output>';
5. Bring back the tablespace online:
And here is the second way:
1. Find the name of the datafile that you're going to migrate just like firt method:
2. Take the datafile offline instead this time:
3. Copy the file using RMAN:
4. Change datafile's name to the new name displayed as output of the command above to update data dictionary:
5. Rename the datafile using RMAN to update ASM. This command is equivalent of "alter database rename file":
6. Recover the new datafile:
7. Bring it online
Both ways do the job. To choose between them is deciding whether tablespace can be taken offline for while or not.
How to Install/Update Java (JDK) on Oracle Linux
2/22/2012 10:12:00 AM
1. Download JDK RPM from Oracle
2. As root:
$ chmod +x jdk-6u30-linux-i586-rpm.bin
$ ./jdk-6u30-linux-i586-rpm.bin.
3. Re-link to new JDK:
$ /usr/sbin/alternatives --install /usr/bin/java java /usr/java/jdk1.6.0_30/bin/java 16030
or alternatively:
Deinstalling Old Oracle Homes After Upgrade
2/16/2012 06:17:00 PM
When Oracle Database and Grid Infrastructure (GI) is updated as Oracle recommended which is out-of-place upgrade, a new Oracle home is created. And a new home means extra disk space. Since no disk has unlimited capacity after a few or many upgrades you need to clean up.
So, assuming we are performing clean up on a single instance with ASM configured and homes to be uninstalled is under /u01/app/oracle/product/11.2.0 let's start with db home:
Deinstall script discovers the configuration. Notice that no database names that are configured in this Oracle home is found. Accept default answers and say yes to continue:
Inventory Location where the Oracle home registered is: /u01/app/oraInventory
No Enterprise Manager configuration to be updated for any database(s)
No Enterprise Manager ASM targets to update
No Enterprise Manager listener targets to migrate
Checking the config status for CCR
Oracle Home exists with CCR directory, but CCR is not configured
CCR check is finished
Do you want to continue (y - yes, n - no)? [n]: y
Deinstall tool does the cleanup smoothly.
Next step is uninstalling GI home which is a bit more tricky. According to Oracle documentation you need to change the permissions of the directory first as root:
GI also has deinstall tool in its home. However if you run it as you do for database, you see the following error though no error logged in the log file.
Don't give up deinstall tool yet. Unzip the 7th of the installation zip files you've downloaded which is the deinstall tool and run it from the unzip directory by giving the home parameter:
The cluster node(s) on which the Oracle home de-installation will be performed are:null
Oracle Home selected for de-install is: /u01/app/oracle/product/11.2.0/grid
Inventory Location where the Oracle home registered is: /u01/app/oraInventory
Skipping Windows and .NET products configuration check
The home being deconfigured is NOT a configured Grid Infrastructure home (/u01/app/oracle/product/11.2.0.2/grid)
ASM was not detected in the Oracle Home
Do you want to continue (y - yes, n - no)? [n]: y
Again say yes to cleanup. When it finishes, you gain ~10GB of your disk space back.
Upgrading Single Instance Oracle Database 11.2.0.1 to 11.2.0.2
2/15/2012 05:25:00 PM
Today I'll upgrade my single instance database from 11.2.0.1 to 11.2.0.2. As you know patch sets are full installations so procedure will be like installing for the very first time except choosing upgrade options.
My database takes advantage of ASM. Therefore we'll start with upgrading Grid Infrastructure. Unzip the 3. of the installation zip files to an appropriate directory such as /tmp. Since 11gR2, upgrades must be done as "out-of-place upgrades". So create the directories for grid and database upgrades.
If you don't show an empty home to installer you get the following error:






Select the new directory as software location. After prerequisite check (nothing came up hopefully) installation will begin and you will be prompted to run root script:


Grid Infrastructure upgrade is completed when the script is finished. You can check the new version by:
Next step is upgrading the database. Unzip the first and the second of the installation zip files and run the installer.





Select the edition you want to install.





When you click "OK" when the script succeeds, Database Upgrade Assistant (DBUA) automatically starts.










At the end a result report is generated.
The whole procedure is pretty much straight forward and goes smoothly.


{kind=link}